Recurrency of a Neural Network - RNN
Here we will be making a way to understand Recurrent Neural Network using Neural Network ideas, so it is required to have some basic working idea of Neural Network. Here is a good resource to get started with Neural Network.
The blog is divided into 4 sections . It will guide you step by step understanding the transition from NN to RNN.
- Drawbacks of Neural Networks by using an example to point out difference
- Making way from Neural Network to Recurrent Neural Network(RNN)
- Birth of RNN
- Backpropogation through time(BPTT)
Starting with first section , we are gonna look at why Neural Networks fails at understanding sequential data.
1. Drawbacks of Neural Networks
The Neural Network as we know is of neurons of previous layer providing inputs to the succeeding layer of neurons. Neural Networks are mere function approximators, where we can either get a probabilistic value (using sigmoid or softmax) or clip a value off (relu functions). After years of research, Neural Networks are the closest idea on how our brain functions.
Let’s see a small example . We will feed two sentences to a neural network
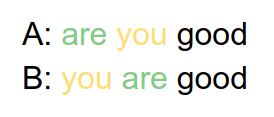
Now, we know that A is a question and B is a declaration. We hope that the network can identify these as two different statements. In order to feed the data to a Neural Network we will use one hot vector to represent the data:
you: [0 1 0]
are: [1 0 0]
good: [0 0 1]
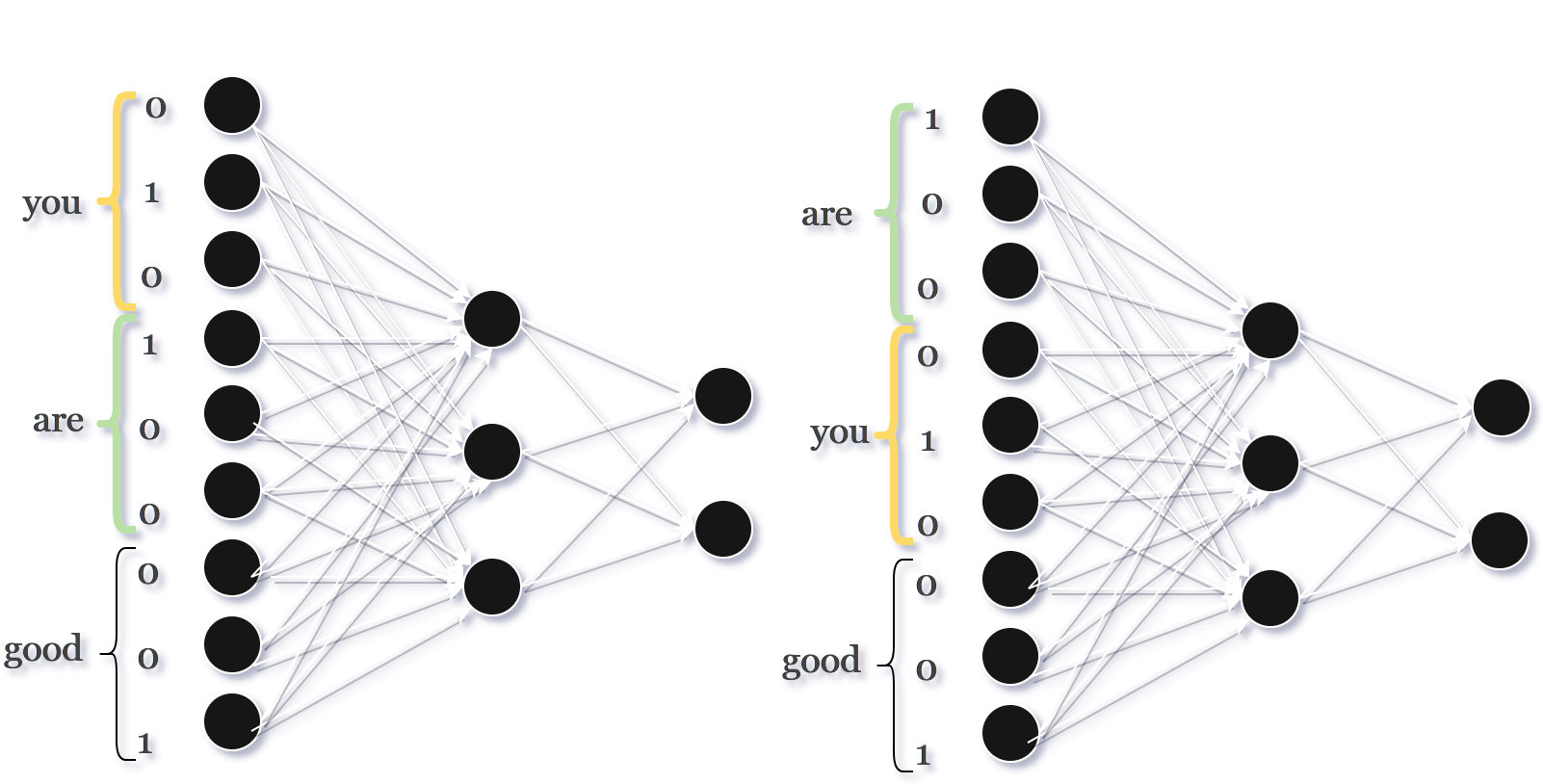
Figure 1: Here the two sentences are different but Neural Networks sees them as same. The ordering of words in sentences is different but the input that neural network sees are [010100001] and [100010001] which doesn’t change the weights and bias of activated neurons in hidden layer.
These two sentences A(“you are good”) and B(“are you good”) at least makes sense to us. Now think of a sentence C (“good you are”). Does it make sense?

Not at all.
When we humans can’t make sense of it, how come the DNN(Dumb Neural Networks) would be able to churn sense out of it.
Machine learning in a nutshell
In Neural Networks,the network states are dependant only on the current time. This makes sense because each neuron are firing based on the current data, and as the training period continues we adjust the weights and biases and it modifies its network based on the data passed . For a given sequential information the past information will always hold information which are crucial to get a desired output. Neural Network current architecture won’t be able to preserve any set of previous information.

This is a major drawback in Neural Network. How can we solve this problem ?
2. Making a way from NN to RNN
Sequential Data:
- In a sequential data, the order in which the data is presented plays an important role.
Example
a->b->c-> ?.
We know the next value is “d” because these given input follows alphabetical order. The value “d” is acknowledged is based on the previous values .
As we saw in section above, the neural networks were not able to capture the sequential information in input. We need an architecture which can adapt to sequential input. Particularly, an architecture which can update weights based on order of the input(word by word for this example). Not like the case of neural network where we dump all information in a go.
Well the idea that we thought was to make a modification in the current knowledge of a Neural Network and bring out a better solution, So the two limitations for the current neural network is:
- Variable size input
- Memory-lization of a neural network
Variable Size Input: It will be very difficult to structure a neural network whose input size constantly varies . If we assume the case of input size being a variable then the output size will be a variable . Thus to model the dynamic nature of input and output , a different network architecture is required.
A simpler solution would be keep input size and output size constant of the Neural Network and to feed inputs externally . Externally meaning that we are feeding the inputs to the hidden layer portion by portion over a period of time impacting the hidden state of network at each time step t.
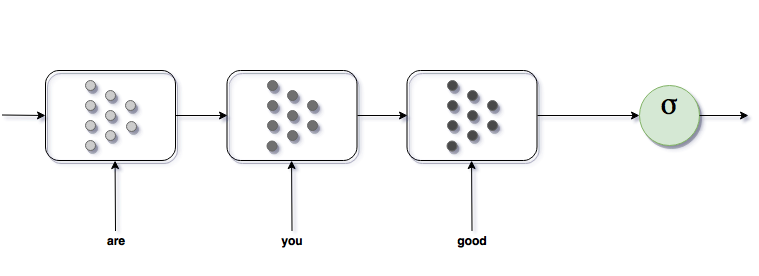
Figure 2: The network is adjusted to the variable size input.
So, only option to consider variable length input and/or output is recurrent neural network, where length of the input and output is fixed like feed forward network. But effect of sequence is considered through recurrency and use of stop sequence signal. Large internal memory in the form of weights can represent internal state of the sequence.
Memory-lization: As mentioned earlier, Neural Network only works based on current parameters alone.Therefore we will add a loop mechanism. In this loop mechanism we calculate the current output based on the previous values. Intuitively what we are doing is basically feeding back the output of the previous values to the current computation. Thus, every hidden layer neuron has the ability to process previous values of its own activity together with new input signals.
For example, sentences starting with ‘are’, ‘what’, ‘which’ are all mapped as question in our mind. The idea behind that intuition is that, we have learned this information over the years and retained the information as “Memory”.
Now since we feed the input over a period of time, our current time step computation depends on it too. Thus the output of the current time step depends on feeded input and the previous output .
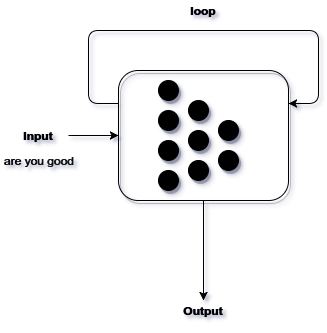
Figure 3: We can see that the current information obtained from the Neural Network, is looped back to the Network for next computation.
The idea which we made till now is a pathway from Neural Network to Recurrent Neural Network(RNN).
3. Birth of RNN
Recurrent neural networks were developed in the 1980s, they had less impact due to computational power of the computers (yep, thank the graphic cards, but blame the cryptocurrency miners for making it expensive). It was first developed by John Hopfield in his Hopfield Network. The Hopfield Network uses an associative memory. An associative memory is a device which accepts an input pattern and generates an output as the stored pattern which is most closely associated with the input.
In RNN, we compute the current value based on the previous state output and current input (from now on we consider external input as input only). This gives the network a proper relation of current input to the previous output .
In Neural Network
- W is the weight for the input
- b is the bias
- x being the input passed.
- sigma is a non-linear function (sigmoid, tanh, relu etc)
This will be the output value of a neuron .
In RNN, we will compute current output based on current input and previous output
- W is the weight of the input at time t
- U is the weight of output at time t-1
- b is the bias
The idea of Memory in RNN is introduced through previous weights U. U provides the significances of the previous output to the current input computation. So it can be imagined as storing some information based on previous value. And the loop mechanism which we earlier assumed can be unfolded into series of one input timestep and predicts one output. This is known as loop unrolling .
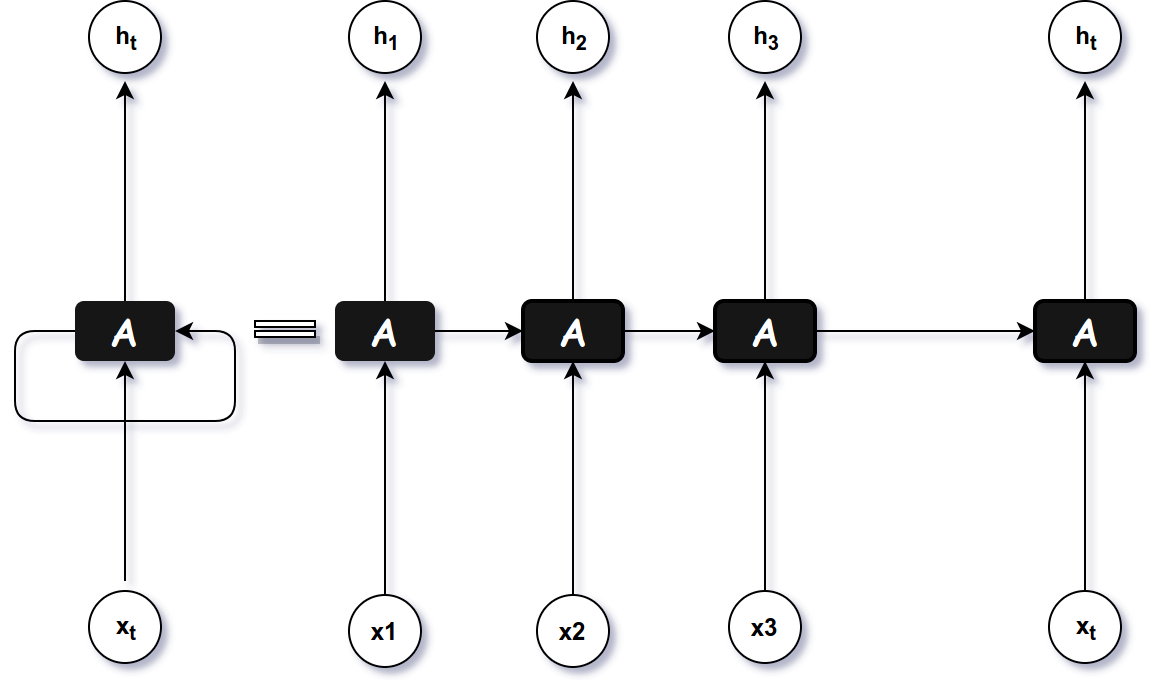
Figure 4: Loop Unrolling idea in RNN
So for our toy example, with the help of RNN we can be able to differentiate between two sentences. The image below shows how RNN solves that problem.
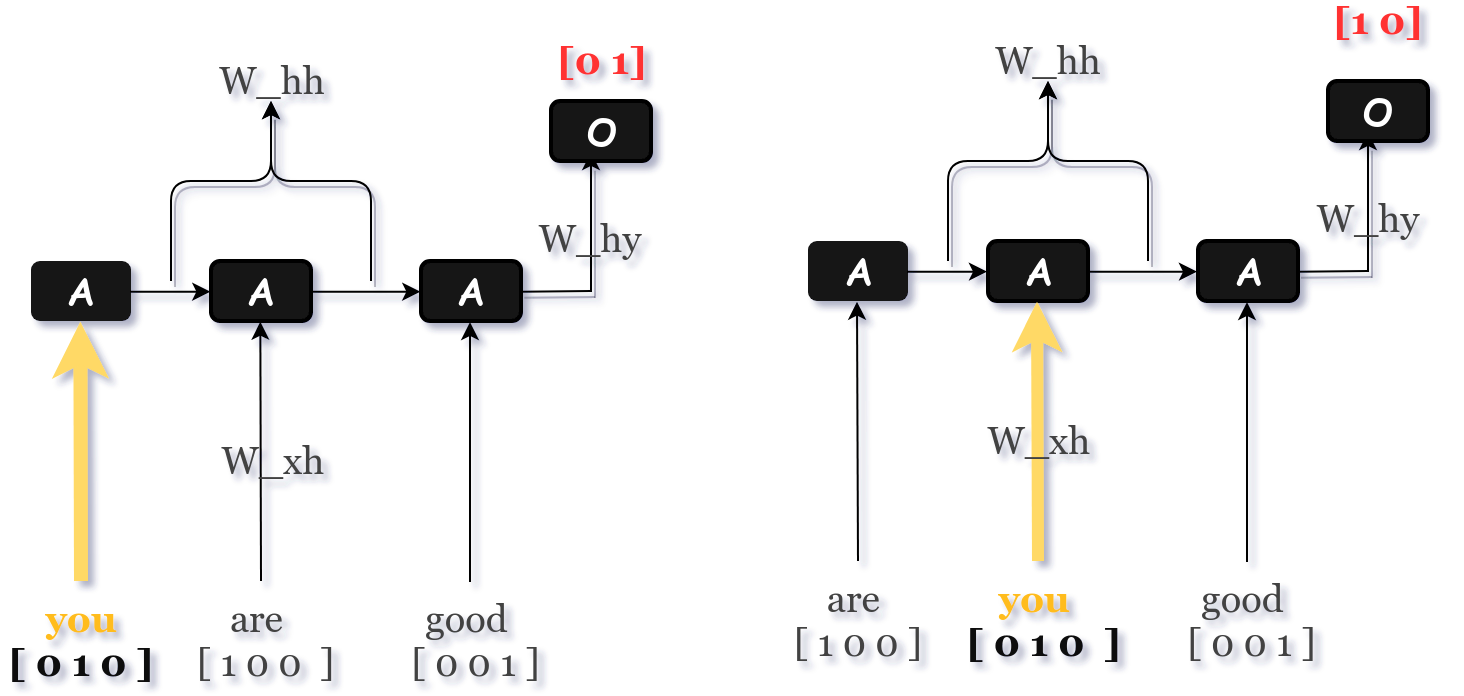
Figure 5: The previous information and the variable length problem is solved using RNN
As we are at the fourth and final section of the blog, let’s see “how to train RNN’s?”
4. Bacpropogation through time
Now let us see how do we train such a model. Training is re-adjusting the weights and biases to be on par with the required output.
The training procedure in the Neural Networks is to calculate final error and then calculate the gradient weights of each neuron, which gives how much influence does the neuron’s weight affect the output. Later we change (increase or decrease) the weight value with a proper learning rate.
The training of RNN is almost the same. Since mentioned earlier we calculate gradients to see the influence of the output. But in our calculation which we did, the current output is dependant on previous output as well.
Therefore each timestep of the unrolled recurrent neural network can be seen as an additional input of the previous output timestep
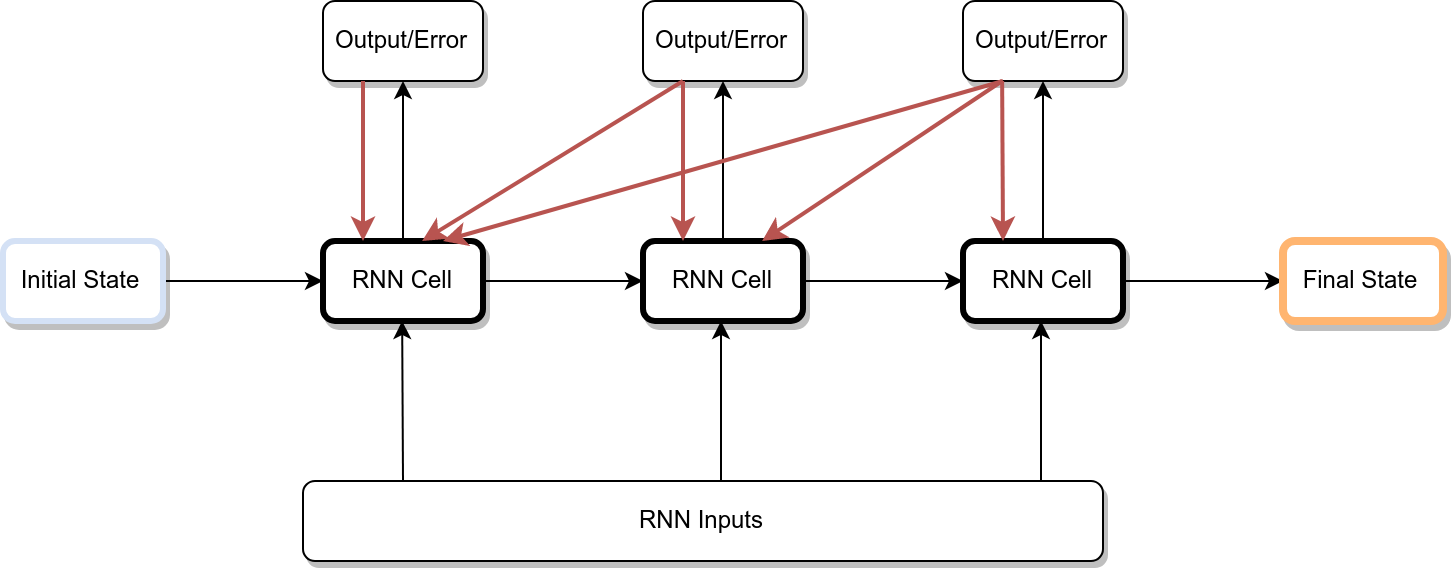
Figure 6: The error for the final RNN state is propagated to the first RNN state
Errors are then calculated and accumulated for each timestep. The network is rolled back up and the weights are updated. We need to calculate the gradient with respect to each time step separately and then add them up.
Summary :
So we covered why neural networks are not appreciated in sequential data and gave a toy example for it. We then introduced RNN and saw how its architecture would help in sequential data .
Future Work:
The next blog will be more on visualizing the memories of the hidden states and more of understanding the influence of the output of the RNN for certain inputs
Notes:
1.With proper construction of rules of the English language a normal Neural Network might be able to differentiate , but giving such a constraints is a tedious task.